Firstly, if you find it troublesome to build your own system, you can easily use the official solution .Just Click here
As a powerful workflow automation tool, n8n contains many professional terms and core concepts, which may be confusing for beginners when they start. To help you quickly grasp n8n and smoothly build automated processes, this document systematically sorts out various key terms from workflows, nodes, data processing to common integations, and explains them with easy-to-understand language and vivid metaphors. Whether you want to understand the basic structure of n8n or want to refer to the functions of specific nodes, you can find clear answers here. I hope this material can become a helpful assistant on your n8n learning journey.
If there are any unclear or ununderstood concepts, it might be helpful to take a look at a brief introduction to deepen your understanding of the terminology and concepts, thereby enabling you to better design your own workflow.
Basic Concepts
Workflow
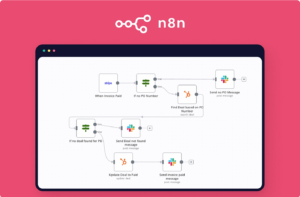
In n8n, a Workflow is an automated process composed of multiple nodes, defining the execution sequence of a series of tasks. One can envision a workflow as an assembly line, with each node responsible for a specific step. When the triggering conditions are met, the workflow commences, executing each node in sequence to accomplish complex automated tasks.
Node:
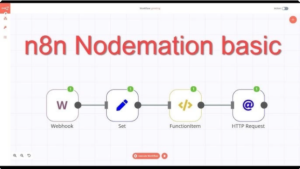
A Node is the basic unit in a workflow, equivalent to a step in a process. Each node has a specific function, such as obtaining data, processing data, or interacting with external services. Novices can understand a node as a Lego brick, and by connecting bricks with different functions, a complete workflow is formed.
Execution:
The Execution of a workflow refers to the process of running the workflow once, which involves the entire operational cycle from the trigger to the completion of each node in sequence. In n8n, workflows can be manually executed for testing purposes, or automatically executed by a trigger after being activated. During execution, execution data and logs are generated, facilitating users to view the operational results of each node.
Active/Inactive:
Setting a workflow to “Active” means enabling it, allowing it to run automatically based on triggers; “Inactive” indicates that the workflow is disabled. An unactivated workflow can only be run manually and will not execute automatically due to triggering events. Newly created workflows are defaulted to be unactivated and require manual activation after confirming that the configuration is correct.
Credential (voucher):
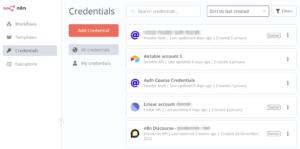
Credential is authentication information used to connect external applications and services. It includes API keys, usernames and passwords, OAuth tokens, etc. In n8n, credentials are centrally managed, and one credential can be reused by multiple nodes. It’s like a lock and a key: the credential is the key, and nodes need the correct key to access external systems.
Parameter:
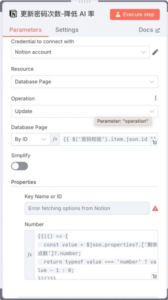
Parameters are configuration options or input values for nodes, used to adjust node behavior. For example, the URL, request method, and request body of an API request node are all configured as parameters. Parameters are like the settings options of household appliances, and users can adjust the parameters of nodes as needed to change the specific operations performed by the nodes.
Expression:

Expression is a special placeholder or formula used to dynamically reference the data of previous nodes or global variables in parameters. Expressions use a syntax similar to ${…} and can execute simple JavaScript code. It allows workflows to make decisions based on real-time data, such as filling the output of a previous node into the input of a subsequent node, just as flexibly as referencing cells in a table with formulas.
Item (data item):
An “item” refers to a data record passed through nodes in a workflow. In n8n, many nodes process data in the form of lists, with each list element being an item. For example, when a node retrieves multiple rows of records from a database, it outputs each row as an item. Subsequent nodes process these items one by one, enabling the cyclic processing of batch data.
JSON (JSON data format):
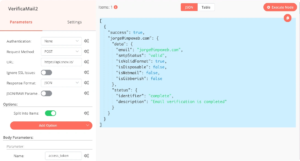
JSON (JavaScript Object Notation) is a lightweight data exchange format, and data in n8n is primarily represented in JSON structure. Simply put, JSON is a text format that organizes data in the form of key-value pairs, akin to a dictionary or table structure, making it easy for humans to read and for machines to parse. For beginners, you can think of node outputs as JSON objects, containing field names and corresponding values.
Binary Data:
Binary Data refers to data in non-textual forms such as files and images. In n8n, binary data is not directly displayed as JSON text, but is attached to data items in a special format. For example, when a node downloads an image, the binary data of the image is included in the data item. You can think of binary data as a courier package, while JSON is the courier label information; n8n attaches the package to the data item for subsequent node usage.
Connection:
A connection is a line between nodes, representing the flow of data and the order of execution. One end of the connection line is connected to the output of the upstream node, and the other end is connected to the input of the downstream node. Data is passed along the connection. It is like a conveyor belt on an assembly line, transporting the output of the previous step to the next step. In the editor canvas, drag the small dots of nodes to draw connection lines and establish relationships between nodes.
Canvas:
Canvas is the main working area in the n8n editor, which is a visual panel for placing and connecting nodes. Users can drag and drop nodes and connect lines on the canvas to build workflow processes. The canvas can be regarded as a whiteboard or map, used to draw automated flowcharts, making it convenient and intuitive to view the structure of the entire workflow.
Template:
Templates are pre-built workflow examples provided by the official team or the community. With templates, novices can quickly import ready-made workflows into their n8n instances, and then fill in credentials or adjust parameters as needed to use them. It’s like having a ready-made recipe; you can just tweak it a bit and put it into action, without having to build the entire process from scratch.
Data Pinning:
Data Pinning is a development and debugging feature that temporarily “pins” the output data of a node. When data pinning is enabled, the fixed data is used as the output of the node every time the workflow is run, without repeatedly requesting new data from the external source. This helps maintain consistent input data for subsequent nodes during debugging, enabling repeated testing of the workflow logic. It should be noted that when the workflow is officially activated for operation, the fixed data is ignored and the latest data is obtained each time.
Sticky Notes:
The n8n editor provides a Sticky Notes feature that allows users to add yellow sticky note-style annotation text on the canvas. These sticky notes can be used to describe the purpose of a certain process, the function of a node, or to remind of important considerations, just like pasting explanatory notes on a flowchart to facilitate understanding of complex workflows for oneself and others.
Tag:
Tag is a custom classification label for workflows. Users can assign one or multiple tags (such as “Marketing” or “Data Synchronization”) to workflows, enabling filtering and management by tag in the workflow list. Tags act as color codes or classification labels for workflows, facilitating quick identification of a relevant group among numerous workflows.
Node Types
Trigger Node:
A trigger node is a special type of node used to determine when a workflow starts executing. It is usually located at the beginning of the workflow and has no input connections. When the trigger condition is met (such as receiving a webhook request or reaching a set time), the trigger node activates the entire workflow. The trigger node can be compared to an alarm clock or a sensor, which, once “triggered”, initiates a series of subsequent actions.
Regular Node:
Ordinary nodes refer to all execution nodes except trigger nodes. They receive data from the previous node for processing and then output the results to the next node. Each ordinary node completes a specific step in the workflow, such as converting data formats, calling external APIs, etc. Compared to trigger nodes, these nodes are more like processing stations in an assembly line, accepting raw materials and producing processed results.
Integration Node:
Integration nodes refer to nodes that interact with external applications or services. For example, nodes that call third-party APIs, read databases, send messages, etc. belong to integration nodes. Using such nodes requires providing credentials for the corresponding services. Integration nodes are like bridges, connecting n8n with the external world, enabling workflows to communicate with various external systems, and achieving cross-system data transmission and operations.
Trigger Nodes
Manual Trigger (Manual Trigger Node):
The manually triggered node is used to manually start the workflow in the editor. After adding this node, users can click the “Execute” button to immediately run the workflow once. It is equivalent to a manual button, facilitating the testing and debugging of workflows without waiting for actual events to occur.
Webhook (Webhook Trigger):
The Webhook node is used to receive external HTTP requests, thereby triggering workflows. n8n generates a unique URL for it. When an external service sends a request to this URL, the workflow is awakened and executed. You can think of Webhook as a network endpoint, through which external events “knock on the door”. Upon receiving the request, n8n starts running the corresponding process. For example,
GitHub can notify n8n of new code pushes through webhooks, thereby triggering subsequent automated tasks.
Schedule Trigger (Scheduled Trigger Node):
The scheduled trigger node initiates workflows according to a preset schedule. For instance, it can be set to occur hourly, at a specific time each day, or scheduled using a Cron expression. It functions as a scheduled alarm clock, automatically waking up workflows when the time is up. It is commonly used for tasks that need to be executed periodically, such as daily data reports and regular backups.
Email Trigger (IMAP) (Email Trigger Node):
The email trigger node monitors new emails in the mailbox through the IMAP protocol. When a new email that meets the set conditions is received in the inbox, the node triggers the workflow execution. This is like assigning an email assistant to n8n, which notifies it whenever a new email arrives
n8n is used for processing. It can be utilized to construct automated email notifications, ticket systems, and more.
RSS Feed Trigger (RSS update trigger node):
The RSS trigger node periodically checks the specified RSS feed for new content. Once a newly published item is detected, it triggers the workflow. It is equivalent to subscribing to a certain information source, which automatically triggers immediately when there is new information, such as monitoring blog updates, new news articles, etc., thereby executing subsequent notification or processing procedures.
Error Trigger (Error Trigger Node):
The Error Trigger node is used to capture unhandled errors that occur in other workflows. When any activated workflow fails to execute and does not handle the error itself, the Error Trigger is triggered. It can be understood as a global exception alarm: once a workflow encounters an error, this node sounds an alarm and initiates a preset error handling process (such as sending notifications or attempting automatic repairs).
Local File Trigger (Local File Trigger Node):
The local file trigger node monitors changes to a local file or directory on the n8n server. When events such as new file creation or file content modification occur, it triggers the corresponding workflow. Similar to file monitors in operating systems, it can be used to automatically process uploaded files, monitor log changes, etc. However, in hosted environments such as n8n Cloud, since access to the underlying file system is not available, this node is usually only suitable for self-hosted instances.
SSE Trigger (Server Push Trigger Node):
SSE (Server-Sent Events) triggers a node to listen for connections from server-pushed events. When the remote server sends events through the SSE channel, the node triggers a workflow. It is equivalent to maintaining a long-lived broadcast channel, responding immediately whenever there is a message. It can be used to receive real-time updates, such as stock quotes, chat messages, and other real-time pushed data sources.
Chat Trigger (Chat Trigger Node):
The chat trigger node is used to build interactive conversational workflows. It provides a chat interface that triggers the workflow to run when a user sends a message and can send AI responses back to the user. In simple terms, this allows n8n to act as a chatbot. It is often used in conjunction with AI nodes to implement question-answering robots, conversational AI assistants, etc., triggering corresponding logic processing and returning answers when receiving user questions.
n8n Trigger (n8n instance trigger node):
The n8n Trigger node monitors events within the n8n system itself. For instance, it is triggered when the current workflow is activated/updated, or when an n8n instance is started or restarted. It can be utilized to execute specific actions upon the occurrence of these system events, such as sending notifications when a workflow is enabled, or executing an initialization process after a system restart.
n8n Form Trigger:
The form trigger node allows workflows to be initiated through web forms. n8n generates a publicly accessible form interface, which, upon submission by the user, triggers the workflow and uses the form content as input data. It can be used to collect external user input
(Such as application forms, survey questionnaires), submitting triggers subsequent automated processing. Correspondingly, n8n also has a form node that can generate interactive forms within the process for further filling out.
MCP Server Trigger (MCP server trigger node):
The MCP Server Trigger node transforms n8n into an MCP (Model Context Protocol) server interface
In simple terms, it allows external AI models or applications to connect to n8n via the MCP protocol and trigger specific workflows to invoke the tool functions provided by n8n. It can be regarded as a webhook for AI models. When AI needs to use a certain capability of n8n, it can send a request through this trigger node, and n8n will execute the corresponding workflow to provide services.
Flow Control
If (condition judgment node):
If nodes implement branching logic in workflows based on set conditions. They check whether the input data meets the conditions. If “yes”, the true branch is taken; if “no”, the false branch is taken. The If node can be likened to a traffic light at a road junction: if the data meets the conditions, one path is taken; otherwise, another path is taken. It is commonly used to determine different processing flows based on data content, such as if the order amount is greater than 100, then the approval process is followed; otherwise, it is automatically processed directly.
Switch (switching node):
The Switch node is similar to the switch/case statement in programming languages, which can route data to different branches based on different values of a certain field. For example, different subsequent nodes are executed based on the value of the order status field (“new”, “processing”, “completed”). It is like a railway switch, which switches tracks according to instructions, allowing data items to follow their corresponding processing branches based on their characteristics.
Merge (merge nodes):
The Merge node is used to combine output data streams from two branches. It offers multiple merging modes, such as pairing the data from the two branches in order, simply concatenating them, or selecting only one. Merge is akin to merging two streams into one, commonly employed when consolidating the results of parallel branches. For instance, one branch might retrieve user information, while the other retrieves order information. Subsequently, Merge can be utilized to amalgamate the two datasets into one for unified processing.
Wait (waiting node):
The “Wait” node will pause the execution of the workflow until a specific condition is met or the timeout period elapses before resuming. This can be used to implement delays or polling waits. For example, setting a wait time of 5 minutes, or waiting for a certain file to appear/a certain status change before continuing the process. It is equivalent to pressing the “pause button” in the process, and “resuming playback” only after the condition is met. It should be noted that long waiting times will occupy workflow running slots, and n8n also provides a special mechanism to optimize the resource consumption of the wait node.
Execute Sub workflow:
This node can invoke another independent workflow within the current workflow, akin to a function call. Through Execute Sub-workflow, users can create common steps as sub-workflows, reusing them across multiple processes to avoid redundant construction. When the Execute Sub-workflow node runs, it triggers the completion of the selected workflow and then returns its results to the current process. It modularizes complex processes, similar to a “large process invoking a sub-process” to accomplish specific tasks, enhancing the organization of workflows
Sex.
Stop and Error (error-terminating node):
This node will immediately cause the workflow to end with an error and output a custom error message. It is typically used to abort the process and throw an error when a certain unexpected situation is met. For example, if incomplete data is detected, the process will be terminated through this node and an error will be prompted. It can be understood as a manually set “emergency brake” to prevent the process from continuing to execute subsequent steps under invalid conditions.
No Operation (No-operation node):
The No Operation (abbreviated as NoOp) node, as the name implies, does nothing. It receives input but does not perform any processing, and outputs it directly as is. This type of node is sometimes used as a placeholder, or in situations where no processing is required in certain branches but the integrity of the workflow structure needs to be maintained. It can be regarded as a placeholder dot in a flowchart, used only for connection and layout, making the flowchart logically clear but not executing additional logic itself.
Loop Over Items (Batch Node):
The node, originally named “Split In Batches”, is designed to divide a data list into smaller batches for sequential processing, thereby achieving the effect of “iterating” through the list. For instance, if there are 100 records, you can configure it to process 10 records at a time, iterating 10 times to complete the entire processing. It serves as a loop controller, preventing performance issues that may arise from processing too much data at once. Upon completion of each batch, it automatically proceeds to the next batch until the list is exhausted or a specified number of iterations is reached.
Data Processing
Edit Fields (Set) (Edit Fields Node):
The “Edit Fields” node (displayed as the “Set” node in the interface) is used to add, modify, or delete fields in data items. Through configuration, it can set new field values, overwrite existing fields, or remove unnecessary fields. Simply put, it allows you to “set” the content of data, such as renaming fields, changing values, or adding new fields based on calculations, similar to editing column values in a table.
Rename Keys (Rename Key Node):
This node is used to batch change the names of fields in data items. By specifying the old key name and the new key name, the field names of the output data can be uniformly modified. For example, the field first_name returned by a third-party API can be renamed to firstname. It has a single function but is practical, equivalent to performing a “renaming surgery” on data fields, facilitating the use of unified field naming in subsequent nodes.
Remove Duplicates (remove duplicate nodes):
The “Remove Duplicates” node examines the input list and eliminates any duplicate items. Duplication can be determined based on the value of one or multiple fields. If multiple pieces of data share the same content in these fields, the first item is retained, and subsequent duplicates are removed. This node serves as a filtering tool, automatically eliminating duplicate records from the list to ensure that the output data set contains no duplicates.
Filter (filter node):
The Filter node filters data items according to set conditions. Records that meet the conditions are output through Match, while those that do not meet the conditions are output through Mismatch (or discarded). It is like applying a filter in Excel, retaining only the rows that meet the conditions. For example, filtering out users whose age is greater than 18. Through Filter, the amount of data can be reduced, focusing on the part of the data that needs to be processed subsequently.
Sort (sorting node):
The Sort node can sort data items according to a specific field (either in ascending or descending order). For instance, it can sort a product list by price from low to high for output. The sorting node is equivalent to performing a “sorting and organizing” operation on the data, facilitating subsequent node processing in order or ensuring that the data is ordered when generating reports. It can sort numbers, dates, strings, and other types of data, making the processing results more controllable and readable.
Limit (limit node):
The Limit node is used to restrict the number of data items that pass through. It allows only the first N data items to pass through, truncating the excess. This is useful when only a limited number of entries need to be processed or to prevent accidentally returning a massive amount of data. It can be likened to cutting the line in half, allowing only the first few people to continue. For example, only the latest 5 records are taken for processing, while the rest are ignored, thus controlling the processing scale of the workflow.
Aggregate (aggregation node):
The Aggregate node groups multiple pieces of data according to a certain field and performs summary calculations on each group of data. Common operations include counting, summing, and averaging. For example, employee data is grouped by “department” and the number of employees in each department is calculated.
Aggregate is equivalent to the GROUP BY operation in a database, which categorizes and aggregates data to produce more concise statistical results, facilitating subsequent analysis or reporting.
Compare Datasets (dataset comparison node):
This node is used to compare the differences between two datasets. It accepts two sets of list data as input and can identify items that are present in A but not in B, or vice versa. Simply put, it performs comparisons such as “set difference/intersection”. For example, comparing the customer list of this month with that of last month to identify new customers and churn customers. Compare Datasets helps automatically detect data changes.
Split Out (Split Node):
The Split Out node splits a single data item containing a list into multiple independent data items. For example, if the previous step returns an array containing multiple elements, Split Out can make each element a separate output data item. It is like breaking a bundle of chopsticks into individual pieces, allowing subsequent nodes to process each item individually. This is very useful in scenarios where each element in the list needs to be traversed and processed.
Summarize (Summary node):
The Summarize node utilizes AI technology to generate concise summaries of given text data. It can read longer texts (such as articles, customer service conversation records) and output a brief summary or a list of key points. It can be likened to automatically writing meeting minutes: input lengthy content, and AI automatically extracts key information. This node is very convenient for scenarios where quick access to the main idea of the content is required.
AI Transform (AI Conversion Node):
The AI Transform node utilizes large language models (such as GPT) to intelligently process input data. For instance, it can generate code snippets based on prompts or perform semantic transformation on data. With its context-aware capability, it can understand the data types and contents of other nodes in the workflow, enabling it to execute complex AI operations. Simply put, this node integrates AI magic into the workflow, allowing it to complete tasks such as content generation, classification, and analysis based on prompts.
Code (code node):
The Code node allows users to directly write JavaScript code to process data. In this node, users can fully customize the operation logic for data, such as complex calculations, data structure conversions, etc. It provides variables like $input to access data from the previous node and can output data of any structure. The Code node is equivalent to a “free manipulation” module prepared for technical users. When built-in nodes cannot meet the needs, a small piece of code can be used to achieve flexible functional extensions.
Markdown (Markdown node):
The Markdown node is used to process Markdown-formatted text. A typical usage is to convert Markdown text into
HTML, which facilitates rendering in emails or web pages. For example, inputting Markdown content with bold and italic tags, and outputting the corresponding HTML tags. This is equivalent to a format translator, allowing workflows to easily handle document format conversion.
HTML (HTML node):
HTML nodes are commonly utilized for parsing or generating HTML content. For instance, one can input a piece of HTML text, extract the values of specific elements from it, or compose an HTML fragment for output. This node proves to be highly practical when it comes to extracting information (such as specific content) from webpage source code or assembling HTML fragments for sending emails. It can be regarded as a simple tool for parsing/generating webpage content.
Date & Time (Date and Time Node):
This node provides formatting and calculation functions for dates and times. It can convert date strings to another format, perform time zone conversion, date addition and subtraction, etc. For example, it can convert 2025-06-21T12:00:00Z to a Beijing time string, or calculate the date three days later. The Date & Time node acts like a calendar/clock assistant, helping you handle various time-related calculations and format conversions in your workflow.
Edit Image (Image Editing Node):
The image editing node can perform simple processing on images, such as resizing, cropping, and adding watermarks. It receives binary image data and generates new image output according to the configured operations. For example, it automatically scales uploaded user avatars to a specified size. Although not as powerful as professional image software, this node is very convenient for lightweight operations such as batch processing of images and generating thumbnails in workflows.
Extract From File (File extraction node):
This node is used to extract structured data from files. Typical applications include reading table data from CSV files and extracting text from PDF or Word documents. For example, if you obtain a CSV file containing a table in the previous step, Extract From File can parse each row as a list of JSON objects representing a data item. It acts like a file content “parser”, translating binary files into easily processed data.
Convert to File:
The Convert to File node converts text or binary data into a file format for output. For instance, it can generate a .txt file from a piece of text or convert JSON data into a CSV file for download. It can be understood as a “packaging” node: packaging data into a file for subsequent email attachments, cloud storage uploads, etc. It is often combined with external notifications or storage for dynamically generating file results.
Read/Write Files from Disk (File Read/Write Node):
This node can read and write files on the local disk of the n8n server. The Read function reads files from the specified path and outputs them as binary data, while the Write function saves the input data as a file. For example, it can automatically read the content of template files or save the processing results as local backup files. It should be noted that in the cloud version of n8n, direct read and write access to local files is usually not available, so this node is mainly used for interacting with the local file system during local deployment.
Debug Helper (Debug Assistant Node):
The debugging assistant node is used to generate test data or intentionally trigger errors in the workflow to assist in debugging. It has multiple operation modes: for example, Generate Random Data can simulate the generation of random test data in a specified format, while Throw Error can artificially throw specific types of errors. This node acts like a multifunctional tester, helping developers verify the error handling mechanism of the workflow or providing sample data to test the logic of subsequent nodes.
Compression (compression node):
The Compression node is used to compress or decompress file data. It supports formats such as ZIP, and can both package and compress multiple files into a single compressed package for output, as well as decompress compressed files into the binary data of multiple files. It acts as a compression/decompression tool in the workflow, and is particularly useful when multiple files need to be transmitted or when processing the contents of a compressed package.
API Related
API (Application Programming Interface):
API stands for Application Programming Interface, which refers to the external access interface provided by software. Through APIs, applications can programmatically access data or functions of another system without using a graphical interface. For example, using HTTP request nodes to call the API of a service to obtain data. APIs are like restaurant menus, listing the “dishes” (functions) that can be ordered. n8n can order dishes and get the desired “service” or data through APIs.
HTTP Request (HTTP request node):
The HTTP Request node is the most commonly used integration node, designed to issue HTTP requests to any web service and obtain responses. It supports methods such as GET, POST, PUT, DELETE, as well as custom request headers and bodies. This node can be utilized to call RESTful APIs, send webhook requests, or access any URL. It serves as a versatile network tool for n8n, facilitating communication with external systems via the HTTP protocol to extract and submit data.
GraphQL (GraphQL Query Node):
The GraphQL node is used to issue query or mutation requests to services that support the GraphQL interface. GraphQL is a new type of API query language that allows clients to request the data they need on demand. Through this node, users can write GraphQL query strings and obtain the corresponding data structure. Compared to ordinary REST interfaces, the GraphQL node provides a more flexible and efficient way to obtain data, making it suitable for integration with services that provide GraphQL endpoints.
FTP (FTP node):
The FTP node is used to connect to an FTP server for uploading, downloading, or listing files. FTP is a traditional file transfer protocol. By providing the FTP server address and credentials, this node can store files on a remote FTP server or retrieve files from it
Retrieve files. This node still comes in handy when interacting with legacy systems or file servers, functioning like an automated FTP client.
SSH (SSH node):
The SSH node enables n8n to connect to remote servers via the Secure Shell protocol to execute commands. After configuring the server address, username and password, or secret key, you can remotely run shell commands and retrieve the output. It is equivalent to opening a remote terminal in the workflow, which automatically logs into the server to execute specified instructions. It is commonly used in scenarios requiring remote control of servers, such as automated deployment and server monitoring.
Git (Git node):
The Git node provides operational capabilities for the Git version control system. It allows operations such as pulling, committing, and pushing to be performed on remote Git repositories. Through this node, n8n can automatically manage code repositories, such as periodically pulling updates from GitHub or committing data to the repository. For CI/CD workflows or code synchronization scenarios, this node can act as an unattended “Git client” to perform daily version control tasks.
LDAP (LDAP node):
The LDAP node is used to interact with LDAP directory services. LDAP is commonly used to store information such as user and permission information for organizations. This node supports querying, adding, or modifying entries in the directory. For example, it can be used to automatically obtain a list of employee information from the company’s LDAP. It can be seen as a tool for workflows to access enterprise phone books, which is very useful when verifying user identities or synchronizing organizational structures.
Send Email (Send Mail Node):
The “Send Email” node enables workflows to directly send emails via the SMTP protocol. After configuring the SMTP server address and credentials, users can set the recipient, subject, and body content (supporting text or HTML), and also add attachments. It functions as an automated mailer, assisting workflows in sending email notifications, reporting results, or communicating with users at appropriate times. When paired with Email Trigger, it can achieve closed-loop automation of email sending and receiving.
Respond to Webhook (Webhook Response Node):
This node is typically used in conjunction with the Webhook Trigger node, to return the result as an HTTP response to the client that originally called the webhook at the end of the workflow. When the workflow is triggered by a webhook request, the default client waits for a response from n8n. Through the Respond to Webhook node, you can customize the returned content (status code
headers, response data), which is equivalent to giving a reply to the visitor at the end of the process. For example, when receiving a form submission webhook, this node can be used to return the processing result or confirmation message to the sender after processing.
Execute Command (Execute Command Node):
The execution command node can run arbitrary command-line instructions on the operating system of the n8n server. This enables workflows to interact with the underlying system, such as executing scripts and invoking system programs. It should be used with caution, as incorrect commands may affect the server. It is like opening a local terminal within the workflow, allowing for the completion of many advanced tasks, such as invoking FFmpeg to process videos and executing Python scripts, thereby expanding the functionality of n8n.
n8n Form (Form Node):
The n8n Form node is used to interact with users and obtain input during workflow execution. It can present a set of questions (form) in chat triggers or other front-end interfaces, wait for users to fill in and submit answers, and then use the user input as the node output. This is similar to popping up a form midway to allow users to participate in decision-making, such as asking a manager to fill in approval comments in an approval workflow. Combined with the n8n Form Trigger, a closed loop from triggering to obtaining user feedback and then continuing the process can be achieved.
Security & Authentication
API Key:
An API key is a simple form of authentication, typically a random string of characters, provided to clients calling the API for authentication purposes. When the client includes the correct API key in the request, the server can recognize it and grant access. It’s like a pass that needs to be presented to enter a certain system. In n8n’s credential configuration, many third-party services require the provision of an API key to prove that the workflow has access permissions.
OAuth2 (OAuth2 Authorization):
OAuth2 is a common open authorization protocol that allows applications to access resources on behalf of users in a restricted manner without exposing user passwords. n8n supports the OAuth2 authorization process. When connecting to a service for the first time, it will redirect to the authorization page of that service for the user to log in and agree to authorize, after which n8n obtains an access token. Compared to directly using passwords, OAuth2 is more secure and supports token expiration refresh. Simply put, it allows n8n to obtain a limited “token key” as a user to call services.
Access Token:
An access token is a credential obtained after authorization, used to call protected APIs on behalf of the user. It is typically issued by an OAuth2 authorization server and has a certain validity period. After the OAuth2 authorization process is completed, n8n will save the obtained access token
Token, and add a request header when calling the API to prove your identity. An access token is like a temporary key, which needs to be refreshed periodically to ensure security.
Basic Auth (Basic Authentication):
Basic authentication is an HTTP standard authentication method. The client passes credentials in the form of Base64 encoding of username:password in the HTTP request header, and the server verifies them accordingly. n8n’s HTTP request node and credentials support Basic Auth, which is like attaching a login username and password to every request. Because it directly transmits passwords, it is generally only used over HTTPS secure channels and is suitable for simple scenarios (such as internal services) or testing purposes.
JWT (JWT Token):
JWT (JSON Web Token) is a compact and secure token for transmitting authentication information. JWT tokens contain a signature, making them tamper-proof. They are commonly used for stateless authentication in REST APIs. n8n provides a JWT node that can be used to generate or verify JWT tokens. For example, the JWT node can be used to verify the token of an incoming request to confirm the identity of the requester
A JWT is like a stamped bill, which both the sender and receiver can verify for authenticity and contains necessary information.
TOTP (One-Time Password Token):
TOTP stands for Time-based One-Time Password Algorithm, such as the common two-step verification 6-digit code. The TOTP node of n8n can generate or verify one-time passwords. For instance, it can be used to generate verification codes to send to users, or to verify whether the verification code submitted by the user is correct. It functions like a small OTP token device, adding a dynamic password to the security verification process
Layer, enhance security.
Crypto (cryptocurrency node):
Crypto nodes are utilized to execute cryptographic operations within workflows, such as hash generation or symmetric encryption. For instance, the SHA-256 algorithm can be employed to compute the hash value of a string, or AES encryption can be applied to text using a designated password. Through Crypto nodes, novices can accomplish common cryptographic and digest tasks without writing code. This is particularly useful in scenarios where sensitive data needs to be encrypted for storage and integrity verification, essentially providing a “mini encryption toolbox” integrated into the workflow.
Popular Integration Nodes
Google Sheets (Google Spreadsheet node):
Used for reading and writing data in Google Sheets online spreadsheets. This node allows adding new rows, updating cells, or reading the data of an entire table. It is commonly used for storing and exchanging data in tabular format, such as appending collected information
To the shared spreadsheet. With the help of credentials, n8n can operate the cloud spreadsheet as a user, achieving functions similar to Excel automation.
Slack (Slack node):
Used for integration with the Slack chat application. It can send messages to specified channels or users, upload files, or respond to Slack events. It is commonly used to automatically send notifications (such as monitoring alerts, process results) to the team’s Slack channel, enabling instant collaborative communication. By using the Slack node, n8n essentially takes over a bot account, allowing it to automatically interact with people on Slack.
Airtable (Airtable node):
Airtable is an online tool that combines spreadsheets with a database. The Airtable node allows for the creation, querying, updating, and other operations of records within an Airtable library. This enables workflows to read and write table data in Airtable. For example, it can automatically save form submission results to Airtable or pull task lists from Airtable for processing. This node is particularly useful in scenarios where Airtable is used as a lightweight database.
Notion (Notion node):
Used for operating Notion notes/databases. Notion nodes can create pages, append content, or query entries in Notion databases. Suitable for automated note-taking and knowledge base management, such as automatically generating daily note templates, synchronizing task information to Notion databases, etc. Linking n8n with Notion allows for the aggregation of scattered automation results into the note-taking system, facilitating subsequent viewing and organization.
GitHub (GitHub Node):
GitHub Node is integrated with the code hosting platform GitHub. It supports operations on repositories, Issues, Pull Requests, etc. For example, it can automatically create Issues, merge Pull Requests, or check new commits in the repository. Developers often use it to connect CI workflows: after code Push, n8n automatically runs tests and records the results on GitHub. Through credential authorization, n8n can complete a series of repository management tasks as a GitHub account.
OpenAI (OpenAI Node):
Used to access AI model services provided by OpenAI (such as GPT-3/4). Through this node, prompts can be sent to
Open up the API of OpenAI and obtain the response text generated by the model. Typical applications include text completion, content summarization, semantic analysis, etc. For example, let the workflow call the GPT model to return an answer based on the input question. The OpenAI node brings the powerful pre-trained AI model capabilities to n8n, making various intelligent text processing possible in workflows.
Discord (Discord node):
Discord nodes are used to interact with the Discord instant messaging platform. They can send messages to server channels, manage members, listen to messages, etc. Similar to Slack, they are used for automatic notifications and robot integration in community or team communication scenarios. For example, when new content is published, a message is automatically broadcasted in the Discord channel. Through n8n, robots in the Discord server can execute complex tasks according to workflow logic.
MySQL (MySQL database node):
Used to connect to MySQL databases and execute SQL queries. Supports operations such as inserting data, updating records, and selecting queries. Suitable for internal data storage within enterprises, n8n can use this to read and write to business databases, enabling automation such as data synchronization and scheduled backups. By providing database connection information, workflows can directly “talk” to MySQL, using query results or writing processing results to the database.
PostgreSQL (PostgreSQL database node):
A Postgres node is similar to a MySQL node, used to connect to a PostgreSQL database and execute SQL commands.
PostgreSQL is renowned for its advanced features, and many applications utilize it for data storage. With the help of this node, n8n can automate
Complex queries, data analysis, or writing data back to the database. For data engineering and data pipeline applications, this node can be used to
n8n seamlessly connects with mainstream backend databases.
MongoDB (MongoDB database node):
The MongoDB node is used to operate the NoSQL document database MongoDB. It supports operations such as inserting, searching, and updating documents. The returned/accepted data is in JSON format, which is highly compatible with the n8n data format. It allows for direct storage of collected semi-structured data into MongoDB, or retrieval and processing of data from MongoDB before writing it back. In scenarios requiring the handling of flexible document-type data, this node is the preferred solution.
Gmail (Gmail node):
A node designed for direct interaction with the Gmail service. Compared to the generic SMTP/IMAP, this node offers convenient operations, such as directly reading emails under a certain label and sending Gmail emails. With OAuth2 credentials, n8n can operate Gmail as a user. For example, it can regularly scan specific emails in the inbox and automatically reply, or transfer emails to other systems. For heavy Gmail users, this is a powerful tool for achieving email automation.
RSS Read (RSS reading node):
The RSS Read node is used to proactively fetch the latest content from a specified RSS feed. Unlike the RSS Trigger, it does not continuously monitor; instead, it fetches RSS data and outputs it immediately upon execution. This is suitable for fetching RSS content when triggered manually or at scheduled intervals, such as fetching news feeds hourly and then processing them. If you want to pull on demand rather than being event-driven, this node provides flexibility, enabling workflows to read data from various RSS/Atom feeds.
Google Drive (Google Cloud Drive node):
The Google Drive node is used to interact with Google Drive. It supports operations such as listing files, uploading/downloading files, and creating folders. For example, it can automatically upload generated report files to a shared drive or periodically synchronize cloud files to a local server. Through Google credential authorization, n8n can operate files in Google Drive as a user, achieving cross-system file management automation and connecting file storage with other applications.
Telegram (Telegram node):
The Telegram node is used for integration with the Telegram messaging app and Bot API. It allows sending messages to users or channels, receiving message updates, and more, through a bot account. Common use cases include building notification bots, sending monitoring alerts or question-and-answer services to administrators or groups via Telegram. Since Telegram provides a concise HTTP API, n8n can easily connect workflows to Telegram using this node, enabling instant messaging notifications and command reception on mobile devices.
Twitter (Twitter node):
Twitter nodes can interact with the Twitter platform, such as automatically posting tweets, reading user timelines, and notifying new followers. By configuring API credentials, workflows can perform operations on behalf of user accounts. This enables automation of social media content publishing and data monitoring, such as scheduled tweets and dynamic updates of social media status based on events. For scenarios requiring interaction with Twitter, this node provides a direct method to extend processes to social networks.
Stripe (Stripe node):
The Stripe node is used for integration with the online payment platform Stripe. It can automatically create/query payment intents, subscriptions, customer information, etc. For example, when an e-commerce website has a new order, n8n can create a Stripe payment intent and send it to the customer to complete the payment, or regularly check the subscription payment status. Leveraging the API provided by Stripe, n8n workflows can intelligently handle payment flows
Integrate financial operations into automation.
Jira (Jira node):
The Jira node is used to interact with Atlassian’s Jira tool, enabling automation of project and issue management. It can create issues, add comments, update statuses, or query issue lists, among other functions. It is suitable for use in IT support or development processes, for example
For instance, automatically recording monitoring alerts as work orders in Jira, or notifying relevant personnel when work orders are updated. Through the process settings of n8n, enterprises can integrate the Jira work order system with other systems to enhance collaboration efficiency.
HubSpot (HubSpot node):
The HubSpot node integrates with the HubSpot CRM/Marketing platform. It can automatically manage contacts, companies, transaction records, and more
CRM data can also trigger and respond to marketing event activities. For instance, when a new potential customer submits a form on the website, n8n creates a HubSpot contact and sends a follow-up email. It automates the process of acquiring and nurturing business leads, which is highly valuable to marketing and sales teams. Through the HubSpot node, n8n becomes an excellent assistant for marketing automation.
Google Calendar (Google Calendar node):
This node can read, create, and update events in Google Calendar. Common uses include automatically scheduling meetings, reminding about schedules, or synchronizing itineraries. For instance, upon receiving a task, an event can be automatically created on the calendar, or a daily summary of tomorrow’s schedule can be sent as a notification. The Google Calendar node allows workflows to directly serve as your schedule assistant, ensuring that important events are recorded and reminded, enabling automation of personal or team time management.
Twilio (Twilio node):
The Twilio node is integrated with the cloud communication platform Twilio. It supports sending SMS messages, WhatsApp messages, or making phone calls. It is commonly used for scenarios such as notifying users of order status, sending verification codes, or making emergency phone calls for alerts. Through the API provided by Twilio, n8n workflows can reach users directly via SMS and phone calls across networks, essentially providing a programmable communication service that makes notifications and interactions ubiquitous.
summary
This document provides a comprehensive overview of the core concepts of n8n, aiming to provide a solid foundation for beginners. Xiangyu starts with the most basic workflow and node, explaining how they constitute the backbone of an automated process. Next, we detail different types of nodes, especially the trigger node as the starting point of the process, the process control node that controls the execution logic, and various data processing nodes used for data processing.
In addition, the documentation also covers key aspects of connecting with the external world, including how to interact with APIs through nodes such as HTTP requests, how to use credentials for secure authentication, and how to leverage n8n’s extensive library of integration nodes to easily connect with Google Sheets, Slack, databases, and various cloud services.
In summary, n8n is a tool that enables the construction of powerful automated processes through the visual orchestration of nodes. By mastering the basic concepts outlined in this document, you will be able to comprehend the working principles of n8n and commence creating your own automated workflows, thereby significantly enhancing work efficiency.